
Companies are capturing and storing more data than ever before as they depend on data for making crucial business decisions, improving service or product offerings, or to provide better services to the end user(customers). Understanding the various big-data storage techniques is essential for establishing a robust data storage pipeline for business intelligence (BI), data analytics, and machine learning (ML) workloads.
To maintain such big data, Data Lake and Data Warehouse architectures have been extensively used by companies. But both these architectures have certain limitations, which we are going to discuss in the later part of the blog leading to the discovery of a new architecture called Data Lakehouse.
However, before diving into the specifics of Data Lakehouse architecture, it is important to first understand Data Lake and Data Warehouse, some of the limitations, and why do we require them in the very first place?
What is Data Lake Architecture
A data lake is a centralised system or repository that stores big data in its natural/raw format, usually objects, blobs or files. You can store any kind of data in any structure (structured, unstructured, semi-structured). For example, a file, an image, music, video, text, or a table. The main purpose of data lake is to make organisational data from different sources accessible to various end users.
Data Lake does not require data transformation before loading like Data warehouse’s ETL mechanism as its schema is defined on the go when the user loads the data and it does not get verified against certain predefined schema.
Limitations of Data Lake architecture
- Poor track record for BI and reporting: In Data Lake architecture BI and reporting are challenging as data lake require additional tools to support SQL queries.
- Compromise in data reliability: Because the data is not structured in any way, data quality, integrity and dependability become a key challenge in this architecture.
- Data Governance: Data governance became hard due to heterogeneous structure with no capability of getting data in a unified manner.
What is Data Warehouse?
Data Warehouse is a centralised repository for the data accumulated from different sources. The data in this case is structured and is verified against predefined schema. It relies on the ETL (extract – transform – load ) mechanism where data needs to be transformed before loading. The purpose of Data Warehouse is to generate reports, feed data to BI tools, predict trends, and train Machine Learning models. The ETL (Extract Load Transform) process is used to store data from multiple sources such as APIs, databases, cloud storage, and so on.
Limitations of Data warehouse architecture
- Inflexibility in processing Data: Only structured data can be processed in data warehouse architecture.
- Costly Storage: It Requires higher cost for managing large amounts of data.
- Incapable of processing Complex Data: Warehouse architecture is generally not suitable for processing complex data for machine learning.
What is Data Lakehouse Architecture?
Data Lakehouse architecture is a combination of two architectures – Data Lake and Data Warehouse, which incorporates the finest elements of both. It supports both Data warehouse architecture’s ACID transaction capabilities, as well as the Data Lake architecture’s scalability, flexibility, and cost efficiency.
What prompted the creation of Data Lakehouse?
Using two tier architectures; Data Lake and Data Warehouse at the same time resulted in significant cost and was difficult to manage as data had to be maintained and synchronised in two distinct locations with two different structures.
Due to the above challenges and limitations of both architectures, many organisations saw the need to combine both architectures into a single system (two tier architecture) so that teams can have the most complete and up-to-date data available for data science, machine learning, and business analytics.
Experts at Data bricks presented this architecture at the conference on Innovation Data System Research (CIDR) in 2021, and Data Lakehouse became the official data management architecture from then.
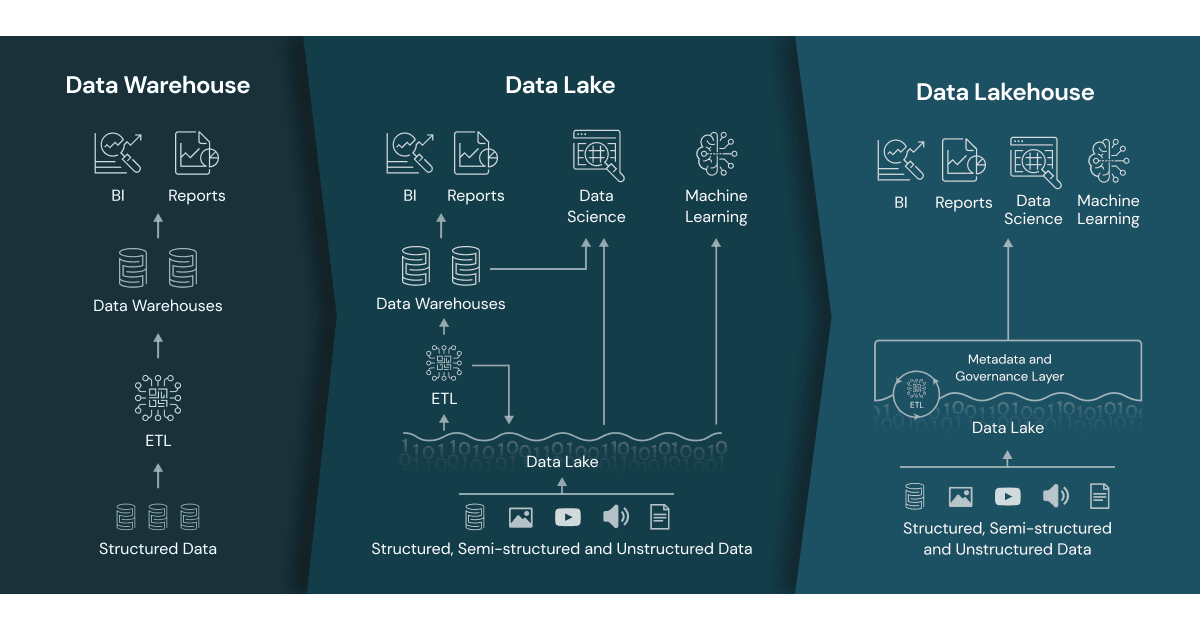
Image source : https://databricks.com/
With the following elements, Data Lakehouse architecture addresses the shortcomings of Data Warehouse and DataLake architecture:
- Reduces Redundancy of data: It unifies the data and reduces duplication of data in case when an organisation is using multiple data sources of Data warehouse and lake.
- Reduces Operational Cost: Since the data is not being stored on several systems the ongoing operational cost will reduce.
- Better organisation of data: It provides better organisation of data in the data lake by enforcing schema.
- Effective use in data analysis, BI and ML: It not only helps in storing large amounts of data and reduces the cost but it also helps in using the data efficiently for analysis, BI, reporting and machine learning.
Thus, a single data Lakehouse provides several advantages over multiple-solution systems, including reduced data movement and redundancy, simplified schema and data governance, and less time and effort administrating. Direct data access for analysis tools and low-cost data storage.
Hire Dedicated Backend Developers:
If you want to migrate or switch from your current database architecture to Datalake house to get the most value out of your data, then please reach out to us on te********@*2h.com. At o2h technology, we have >5 years of experience database developers who can guide you through the whole process and execute the migration of your current database architecture to Data Lake House.
You can hire dedicated Data Lake House developers from o2h technology. The whole process is quite simple and transparent. Book a free consultation call directly with our dedicated developer to understand Data Lake house in detail and in case you have any further technical queries.








